
The race to object recognition is on, and you’ve probably seen tons about the upcoming release of Microsoft HoloLens and Snapchat Spectacles V2. However, while the race to artificial intelligence is rapidly advancing achievements in complex machine learning, speech recognition (eg. Amazon Alexa and Apple Inc’s Siri), and the development of artificial neural networks, the advancements in this space have been heavily dependent on feature detection. In brief, feature detection detects, compiles, and categorises a set of features in order to interpret an input. While this is effective for voice recognition (with some exceptions (eg: Amazon Echo) and face recognition (e.g. Facebook), this can fail spectacularly for object recognition, as it did for Google’s Deep Dream project and Blippar¹.

The key to understanding the feature detection problem is through conceptualizing object recognition as a two-step process; object detection and object interpretation. Object detection identifies and distinguishes the object you wish to recognize according to its relevant features, limiting the surrounding ‘noise’; object recognition involves sending that object for interpretation, by searching for like objects within a dataset. As described in an article by Jessica Birkett of the University of Melbourne, the obstacle to effective object recognition and deep learning exhibited by Google’s Deep Dream project is the vulnerability of neural networks to over-interpretation and generalization of features in the object detection stage. The challenge for object recognition then is, how do we overcome the problems with feature detection, or can we bypass them altogether?
In the following, we survey the evolution of the tech-architectures across the competing object recognition models from 2012 up to today. We’ll provide a review of the strongest technology in the object detection space to review the innovations being applied to surmount the obstacles.
Datasets and Performance Metric
Our evaluation metric measures the performance of the tech on two elements: processing speed, and accuracy. A limitation of the survey is the diversity of datasets against which the technology is applied. Several datasets have been released for object detection challenges. We’ve limited our survey to four datasets: (PASCAL VOC, COCO, ImageNet). Thus the cited accuracies cannot be directly compared per se. Below, we provide a summary of these and their status as industry best practice.
Datasets
The PASCAL Visual Object Classification (PASCAL VOC) dataset is a well-known dataset for object detection, classification, segmentation of objects and so on. There are 8 different challenges spanning from 2005 to 2012, each of them having its own specificities. There are around 10 000 images for training and validation containing bounding boxes with objects. Although, the PASCAL VOC dataset contains only 20 categories, it is still considered as a reference dataset in the object detection problem.
ImageNet has released an object detection dataset since 2013 with bounding boxes. The training dataset is composed of around 500 000 images only for training and 200 categories. It is rarely used because the size of the dataset requires an important computational power for training. Also, the high number of classes complicates the object recognition task. A comparison between the 2014 ImageNet dataset and the 2012 PASCAL VOC dataset is available here.
On the other hand, the Common Objects in COntext (COCO) dataset is developed by Microsoft and detailed by T.-Y.Lin and al. (2015). This dataset is used for multiple challenges: caption generation, object detection, key point detection and object segmentation. We focus on the COCO object detection challenge consisting in localizing the objects in an image with bounding boxes and categorizing each one of them between 80 categories. The dataset changes each year but usually is composed of more than 120 000 images for training and validation, and more than 40 000 images for testing. The test dataset has been recently cut into the test-dev dataset for researchers and the test-challenge dataset for competitors. Both associated labeled data are not publicly available to avoid overfitting on the test dataset.

Performance Metric
Specific performance metrics have been developed to take into account the spatial position of the detected object and the accuracy of the predicted categories. The commonly used metric used for object detection challenges is called the mean Average Precision (mAP).
The object detection challenge is, at the same time, a regression and a classification task. Object detection involves sectioning an image to generate ‘boxes’, which act as theories concerning the relationship of features to each other (e.g. through correlation, association). To assess spatial precision, it is necessary to remove the boxes with low confidence (usually, the model outputs many more boxes than actual objects). Then, we use the Intersection over Union (IoU) area, a value between 0 and 1. It corresponds to the overlapping area between the predicted box and the ground-truth box (that is, the ideal output of an algorithm, or the true state of the object in the frame). The higher the IoU, the better the predicted location of the box for a given object. Usually, we keep all bounding box candidates with an IoU greater than some threshold.
In binary classification, the Average Precision (AP) metric is a summary of the precision-recall curve, details are provided here. It is simply the mean of the Average Precisions computed over all the classes of the challenge. The mAP metric avoids to have extreme specialization in few classes and thus weak performances in others. The mAP score is usually computed for a fixed IoU but a high number of bounding boxes can increase the number of candidate boxes.²
Region-based Convolutional Network (R-CNN)
The first models intuitively begin with the region search and then perform the classification. In R-CNN, the selective search method developed by J.R.R. Uijlings and al. (2012) is an alternative to exhaustive search in an image to capture object location. It initializes small regions in an image and merges them with a hierarchical grouping. Thus the final group is a box containing the entire image. The detected regions are merged according to a variety of color spaces and similarity metrics. The output is a few number of region proposals which could contain an object by merging small regions.

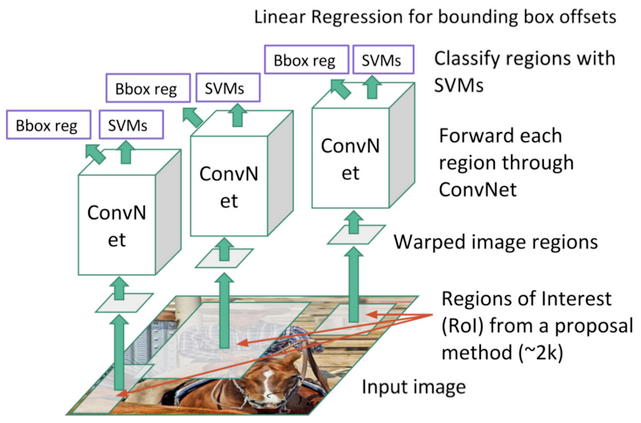
The R-CNN model (R. Girshick et al., 2014) combines the selective searchmethod to detect region proposals and deep learning to find out the object in these regions. Each region proposal is resized to match the input of a CNN from which we extract a 4096-dimension vector of features. The features vector is fed into multiple classifiers to produce probabilities to belong to each class. Each one of these classes has a SVM classifier trained to infer a probability to detect this object for a given vector of features. This vector also feeds a linear regressor to adapt the shapes of the bounding box for a region proposal and thus reduce localization errors.
The CNN model described by the authors is trained on the 2012 ImageNet dataset of the original challenge of image classification. It is fine-tuned using the region proposals corresponding to an IoU greater than 0.5 with the ground-truth boxes. Two versions are produced, one version is using the 2012 PASCAL VOC dataset and the other the 2013 ImageNet dataset with bounding boxes. The SVM classifiers are also trained for each class of each dataset.
The best R-CNNs models have achieved a 62.4% mAP score over the PASCAL VOC 2012 test dataset (22.0 points increase w.r.t. the second best result on the leader board) and a 31.4% mAP score over the 2013 ImageNet dataset (7.1 points increase w.r.t. the second best result on the leader board).
Fast Region-based Convolutional Network (Fast R-CNN)
The purpose of the Fast Region-based Convolutional Network (Fast R-CNN) developed by R. Girshick (2015) is to reduce the time consumption related to the high number of models necessary to analyse all region proposals.
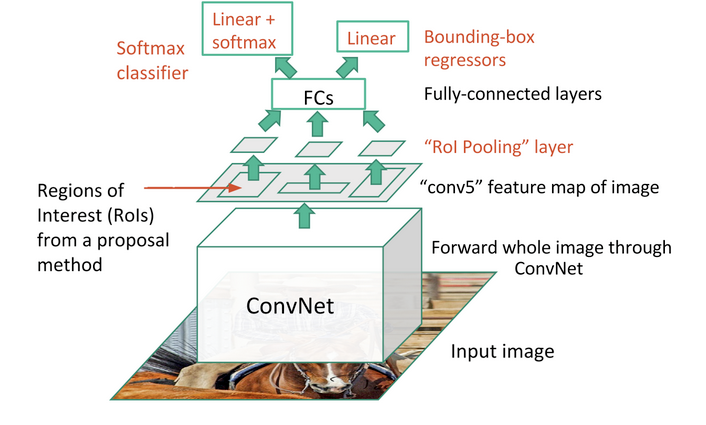
A main CNN with multiple convolutional layers is taking the entire image as input instead of using a CNN for each region proposals (R-CNN). Region of Interests (RoIs) are detected with the selective search method applied on the produced feature maps. Formally, the feature maps size is reduced using a RoI pooling layer to get valid Region of Interests with fixed heigh and width as hyperparameters. Each RoI layer feeds fully-connected layers³ creating a features vector. The vector is used to predict the observed object with a softmax classifier and to adapt bounding box localizations with a linear regressor.
The best Fast R-CNNs have reached mAp scores of 70.0% for the 2007 PASCAL VOC test dataset, 68.8% for the 2010 PASCAL VOC test dataset and 68.4% for the 2012 PASCAL VOC test dataset.
Faster Region-based Convolutional Network (Faster R-CNN)
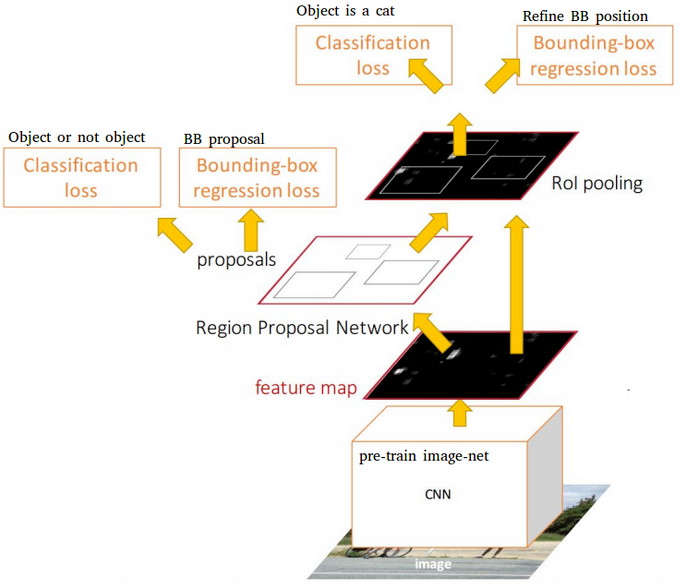
Region proposals detected with the selective search method were still necessary in the previous model, which is computationally expensive. S. Ren and al. (2016) have introduced Region Proposal Network (RPN) to directly generate region proposals, predict bounding boxes and detect objects. The Faster Region-based Convolutional Network (Faster R-CNN) is a combination between the RPN and the Fast R-CNN model.
A CNN model takes as input the entire image and produces feature maps. A window of size 3×3 slides all the feature maps and outputs a features vector linked to two fully-connected layers, one for box-regression and one for box-classification. Multiple region proposals are predicted by the fully-connected layers. A maximum of k regions is fixed thus the output of the box-regression layer has a size of 4k (coordinates of the boxes, their height and width) and the output of the box-classification layer a size of 2k (“objectness” scores to detect an object or not in the box). The k region proposals detected by the sliding window are called anchors.
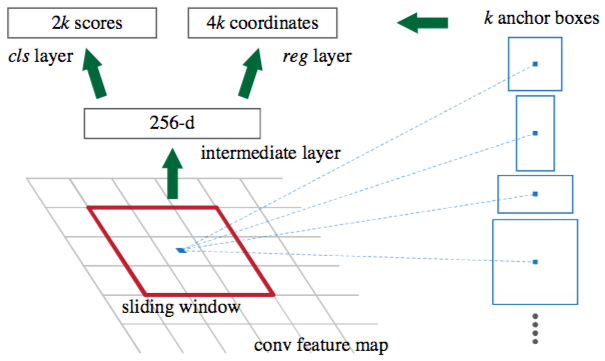
When the anchor boxes are detected, they are selected by applying a threshold over the “objectness” score to keep only the relevant boxes. These anchor boxes and the feature maps computed by the initial CNN model feeds a Fast R-CNN model.
Faster R-CNN uses RPN to avoid the selective search method, it accelerates the training and testing processes, and improve the performances. The RPN uses a pre-trained model over the ImageNet dataset for classification and it is fine-tuned on the PASCAL VOC dataset. Then the generated region proposals with anchor boxes are used to train the Fast R-CNN. This process is iterative.
The best Faster R-CNNs have obtained mAP scores of 78.8% over the 2007 PASCAL VOC test dataset and 75.9% over the 2012 PASCAL VOC test dataset. They have been trained with PASCAL VOC and COCO datasets. One of these models⁴ is 34 times faster than the Fast R-CNN using the selective search method.
Region-based Fully Convolutional Network (R-FCN)
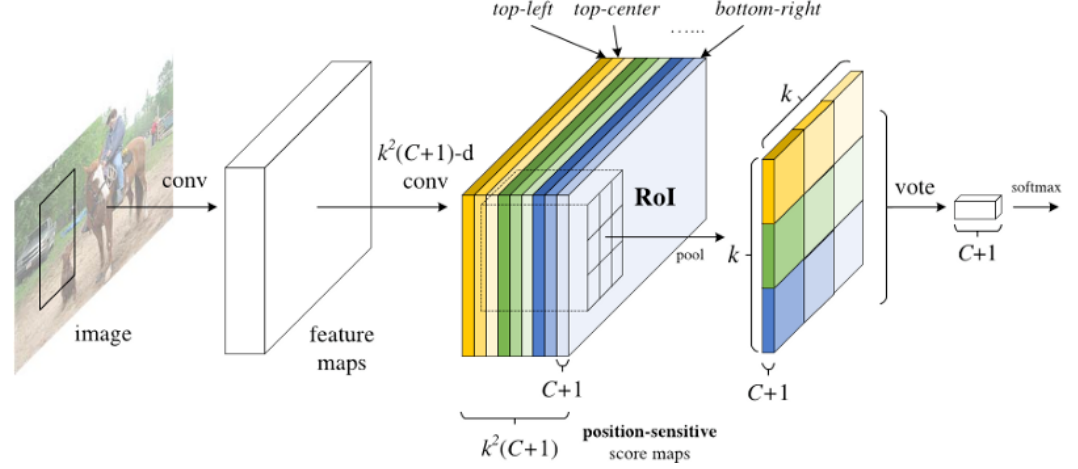
Fast and Faster R-CNN methodologies consist in detecting region proposals and recognize an object in each region. The Region-based Fully Convolutional Network (R-FCN) released by J. Dai and al. (2016) is a model with only convolutional layers⁵ allowing complete back propagation for training and inference. The authors have merged the two basic steps in a single model to take into account simultaneously the object detection (location invariant) and its position (location variant).
A ResNet-101 model takes the initial image as input. The last layer outputs feature maps, each one is specialized in the detection of a category at some location. For example, one feature map is specialized in the detection of a cat, another one in a banana and so on. Such feature maps are called position-sensitive score maps because they take into account the spatial localization of a particular object. It consists of k*k*(C+1) score maps where k is the size of the score map, and C the number of classes. All these maps form the score bank. Basically, we create patches that can recognize part of an object. For example, for k=3, we can recognize 3×3 parts of an object.
In parallel, we need to run a RPN to generate Region of Interest (RoI). Finally, we cut each RoI in bins and we check them against the score bank. If enough of these parts are activated, then the patch vote ‘yes’, I recognized the object.
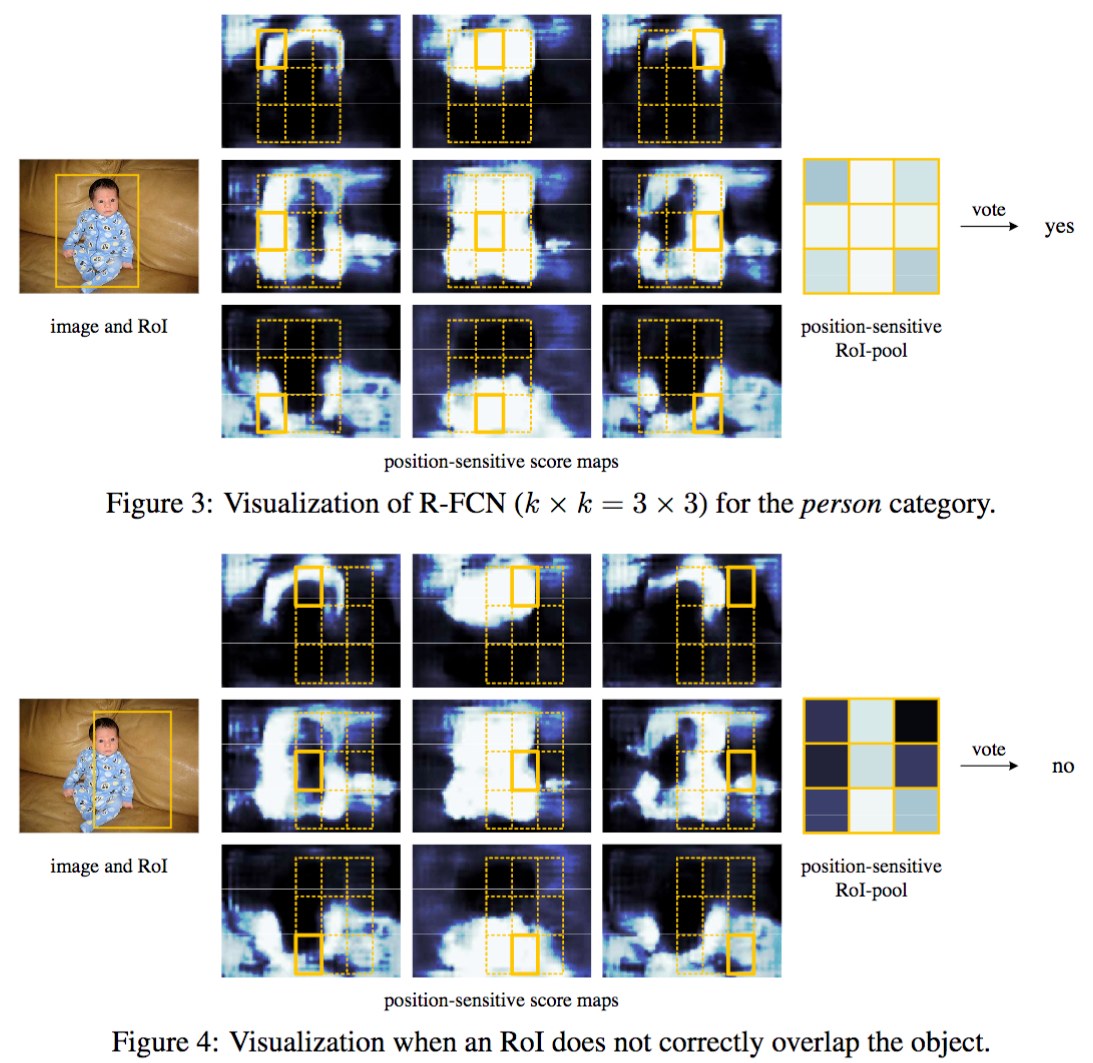
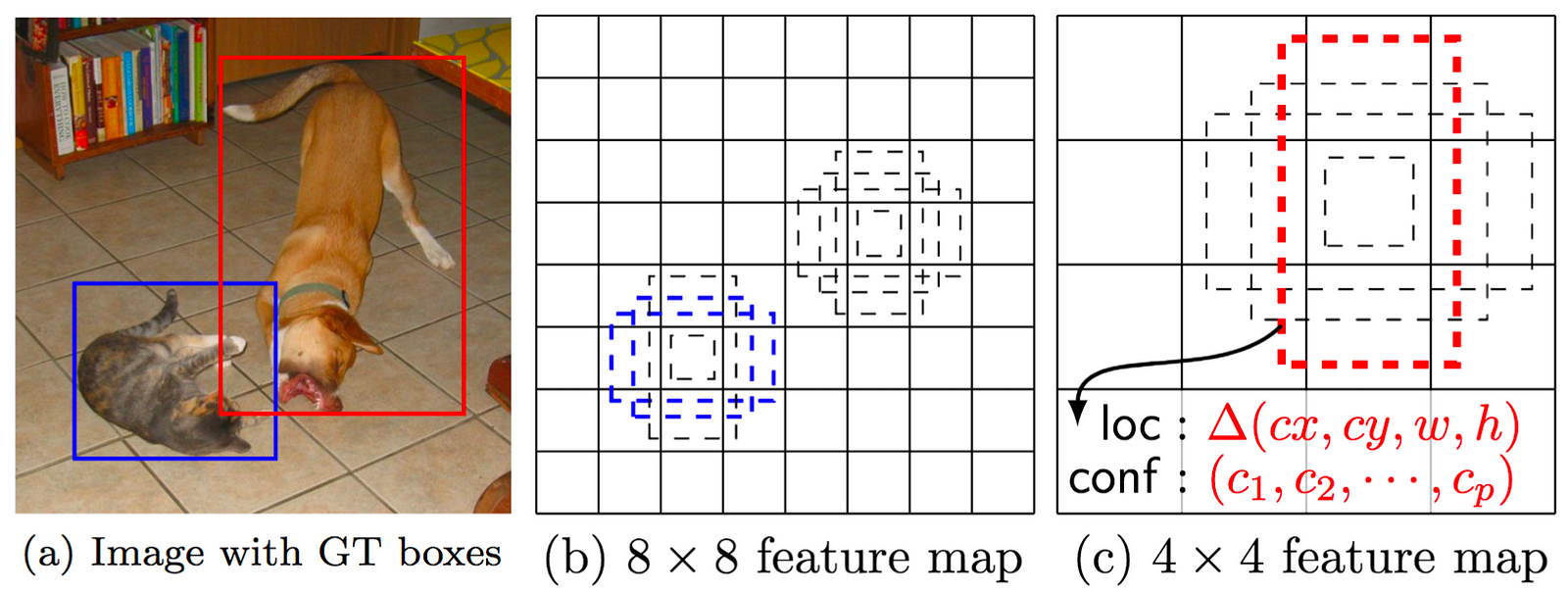
J. Dai and al. (2016) have detailed an example displayed below. The figures show the reaction of a R-FCN model specialized in detecting a person. For a RoI in the center of the image (Figure 3), the subregions in the feature maps are specific to the patterns associated to a person. Thus they vote for ‘yes, there is a person at this location’. In the Figure 4, the RoI is shifted to the right and it is no longer centred on the person. The subregions in the feature maps do not agree on the person detection, thus they vote ‘no, there is no person at this location’.
The best R-FCNs have reached mAP scores of 83.6% for the 2007 PASCAL VOC test dataset and 82.0%, they have been trained with the 2007, 2012 PASCAL VOC datasets and the COCO dataset. Over the test-dev dataset of the 2015 COCO challenge, they have had a score of 53.2% for an IoU = 0.5 and a score of 31.5% for the official mAP metric. The authors noticed that the R-FCN is 2.5–20 times faster than the Faster R-CNN counterpart.
You Only Look Once (YOLO)
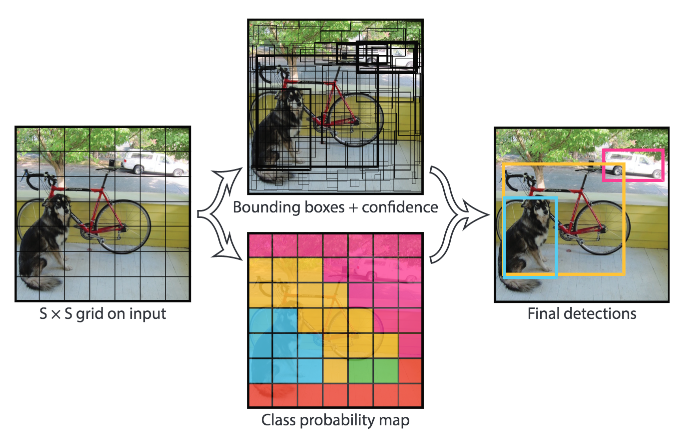
The YOLO model (J. Redmon et al., 2016)) directly predicts bounding boxes and class probabilities with a single network in a single evaluation. The simplicity of the YOLO model allows real-time predictions.
Initially, the model takes an image as input. It divides it into an SxS grid. Each cell of this grid predicts B bounding boxes with a confidence score. This confidence is simply the probability to detect the object multiply by the IoU between the predicted and the ground truth boxes.
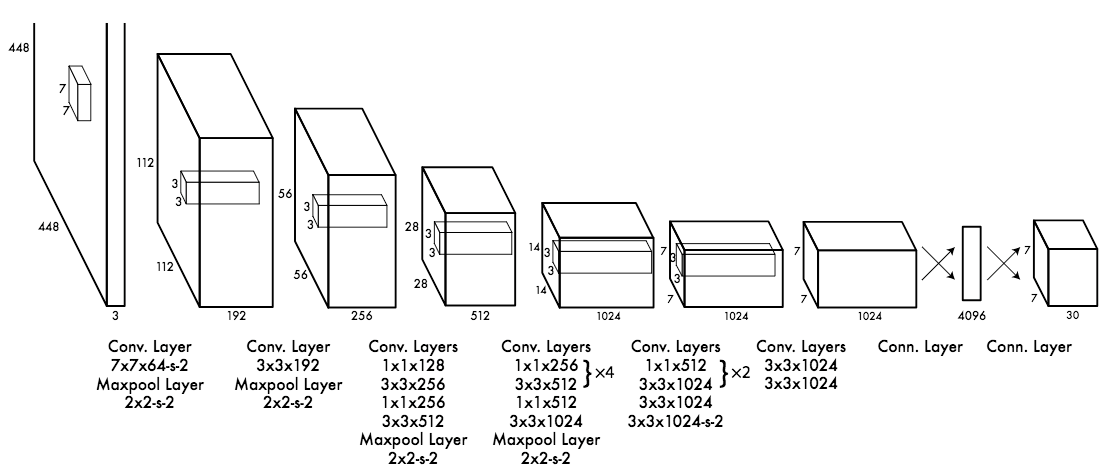
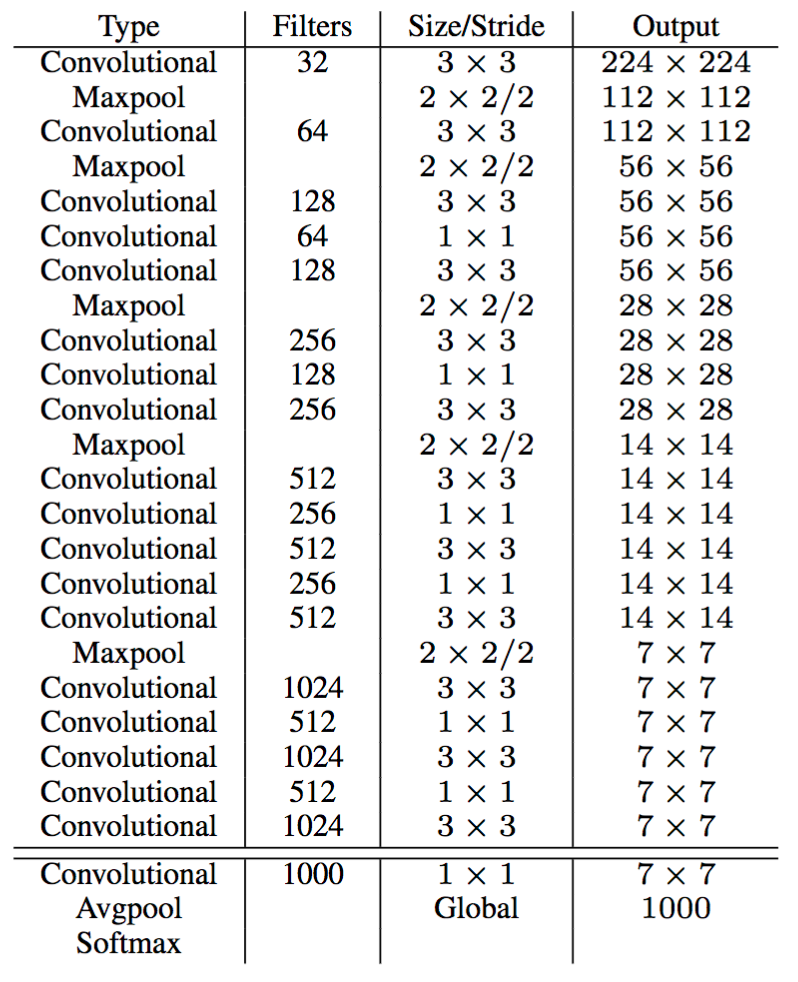
The CNN used is inspired by the GoogLeNet model introducing the inception modules. The network has 24 convolutional layers followed by 2 fully-connected layers. Reduction layers with 1×1 filters⁶ followed by 3×3 convolutional layers replace the initial inception modules. The Fast YOLO model is a lighter version with only 9 convolutional layers and fewer number of filters. Most of the convolutional layers are pretrained using the ImageNet dataset with classification. Four convolutional layers followed by two fully-connected layers are added to the previous network and it is entirely retrained with the 2007 and 2012 PASCAL VOC datasets.
The final layer outputs a S*S*(C+B*5) tensor corresponding to the predictions for each cell of the grid. C is the number of estimated probabilities for each class. B is the fixed number of anchor boxes per cell, each of these boxes being related to 4 coordinates (coordinates of the center of the box, width and height) and a confidence value.
With the previous models, the predicted bounding boxes often contained an object. The YOLO model however predicts a high number of bounding boxes. Thus there are a lot of bounding boxes without any object. The Non-Maximum Suppression (NMS) method is applied at the end of the network. It consists in merging highly-overlapping bounding boxes of a same object into a single one. The authors noticed that there are still few false positive detected.
The YOLO model has a 63.7% mAP score over the 2007 PASCAL VOC dataset and a 57.9% mAP score over the 2012 PASCAL VOC dataset. The Fast YOLO model has lower scores but they have both real time performances.
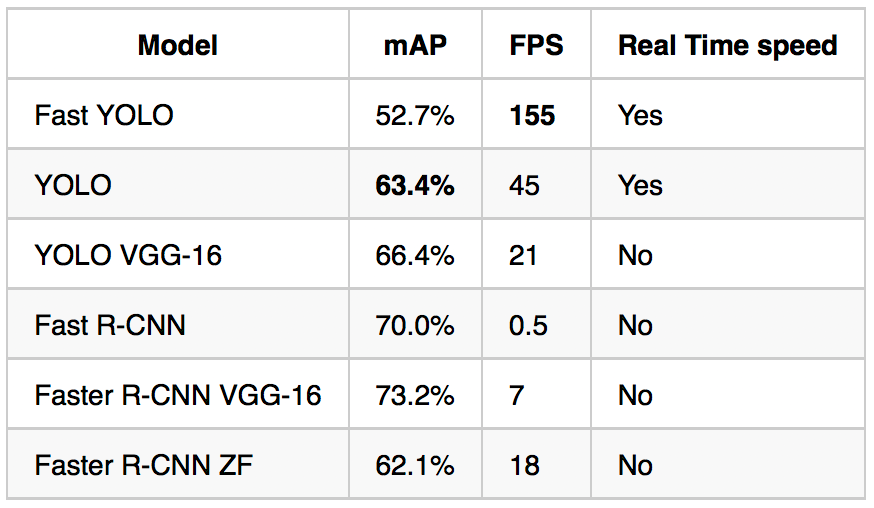
Single-Shot Detector (SSD)
Similarly to the YOLO model, W. Liu et al. (2016) have developed a Single-Shot Detector (SSD) to predict all at once the bounding boxes and the class probabilities with a end-to-end CNN architecture.
The model takes an image as input which passes through multiple convolutional layers with different sizes of filter (10×10, 5×5 and 3×3). Feature maps from convolutional layers at different position of the network are used to predict the bounding boxes. They are processed by a specific convolutional layers with 3×3 filters called extra feature layers to produce a set of bounding boxes similar to the anchor boxes of the Fast R-CNN.
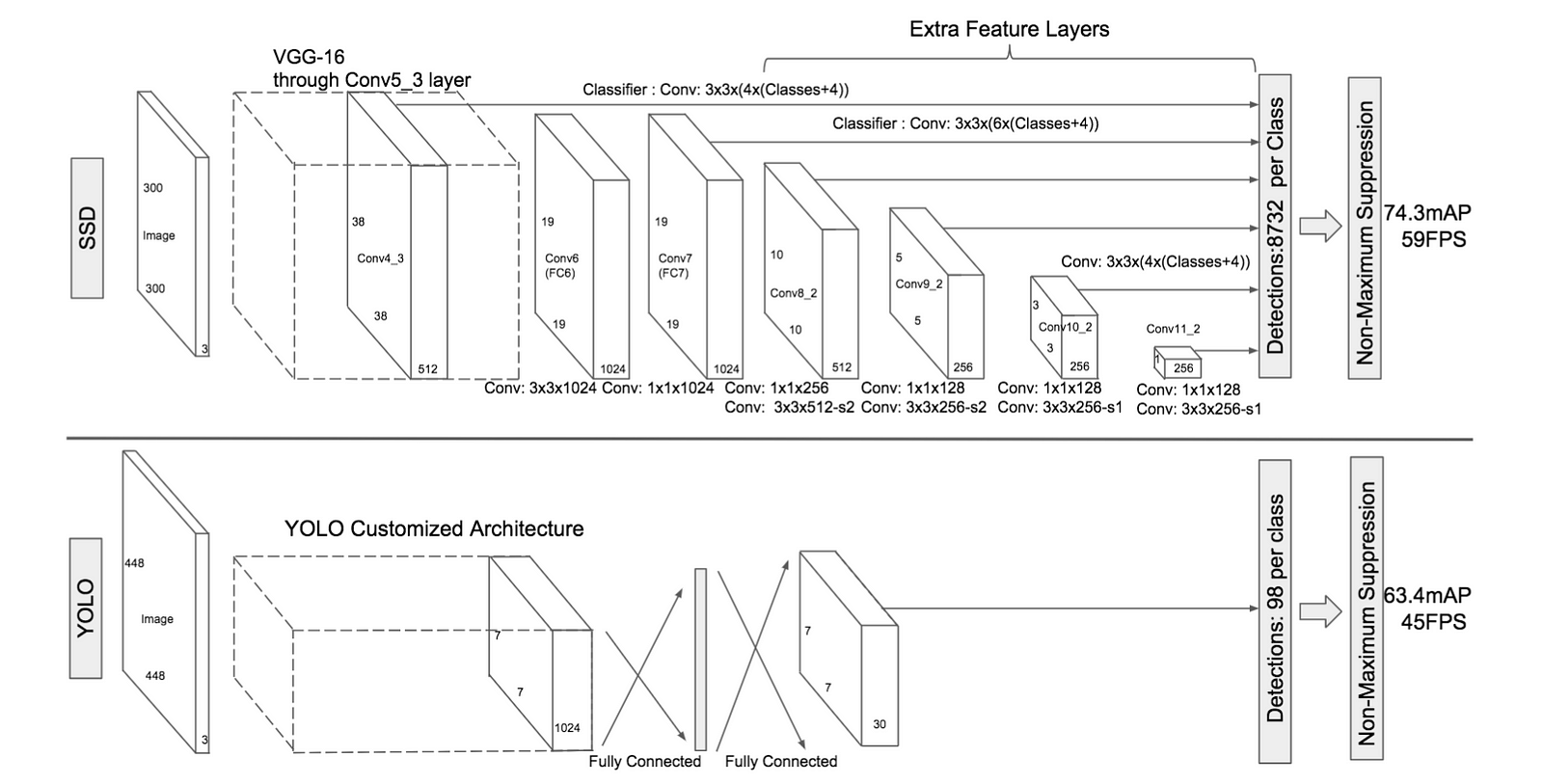
Each box has 4 parameters: the coordinates of the center, the width and the height. At the same time, it produces a vector of probabilities corresponding to the confidence over each class of object.
The Non-Maximum Suppression method is also used at the end of the SSD model to keep the most relevant bounding boxes. The Hard Negative Mining(HNM) is then used because a lot of negative boxes are still predicted. It consists in selecting only a subpart of these boxes during the training. The boxes are ordered by confidence and the top is selected depending on the ratio between the negative and the positive which is at most 1/3.
W. Liu et al. (2016) distinguish the SSD300 model (the architecture is detailed on the figure above) and the SSD512 model which is the SSD300 with an extra convolutional layer for prediction to improve performances. The best SSDs models are trained with the 2007, 2012 PASCAL VOC datasets and the 2015 COCO dataset with data augmentation. They have obtained mAP scores of 83.2% over the 2007 PASCAL VOC test dataset and 82.2% over the 2012 PASCAL VOC test dataset. Over the test-dev dataset of the 2015 COCO challenge, they have had a score of 48.5% for an IoU = 0.5, 30.3% for an IoU = 0.75 and 31.5% for the official mAP metric.
YOLO9000 and YOLOv2
J. Redmon and A. Farhadi (2016) have released a new model called YOLO9000 capable of detecting more than 9000 object categories while running in almost real time according to the authors. They also provide improvements over the initial YOLO model to improve its performances without decreasing its speed (around 10 images per second on a recent mobile according to our implementation).
YOLOv2
The YOLOv2 model is focused on improving accuracy while still being a fast detector. Batch normalization is added to prevent overfitting without using dropout. Higher resolution images are accepted as input: the YOLO model uses 448×448 images while the YOLOv2 uses 608×608 images, thus enabling the detection of potentially smaller objects.
The final fully-connected layer of the YOLO model predicting the coordinates of the bounding boxes has been removed to use anchor boxes in the same way as Faster R-CNN. The input image is reduced to a grid of cells, each one containing 5 anchor boxes. YOLOv2 uses 19*19*5=1805 anchor boxes by image instead of 98 boxes for the YOLO model. YOLOv2 predicts correction of the anchor box relative to the location of the grid cell (the range is between 0 and 1) and selects the boxes according to their confidence as the SSD model. The dimensions of the anchor boxes has been fixed using k-means on the training set of bounding boxes.
It uses a ResNet-like architecture to stack high and low resolution feature maps to detect smaller objects. The “Darknet-19” is composed of 19 convolutional layers with 3×3 and 1×1 filters, groups of convolutional layers are followed by maxpooling layers to reduce the output dimension. A final 1×1 convolutional layer outputs 5 boxes per cell of the grid with 5 coordinates and 20 probabilities each (the 20 classes of the PASCAL VOC dataset).
The YOLOv2 model trained with the 2007 and 2012 PASCAL VOC dataset has a 78.6% mAP score over the 2007 PASCAL VOC test dataset with a FPS value of 40. The model trained with the 2015 COCO dataset have mAP scores over the test-dev dataset of 44.0% for an IoU = 0.5, 19.2% for an IoU = 0.75 and 21.6% for the official mAP metric.
YOLO9000
The authors have combined the ImageNet dataset with the COCO dataset in order to have a model capable of detecting precise objects or animal breed. The ImageNet dataset for classification contains 1000 categories and the 2015 COCO dataset only 80 categories. The ImageNet classes are based on the WordNet lexicon developed by the Princeton University which is composed of more than 20 000 words. J. Redmon and A. Farhadi (2016) detail a method to construct a tree version of the WordNet. A softmax is applied on a group of labels with the same hyponym when the model predicts on an image. Thus the final probability associated to a label is computed with posterior probabilities in the tree. When the authors extend the concept to the entire WordNet lexicon excluding under-represented categories, they obtain more than 9 000 categories.
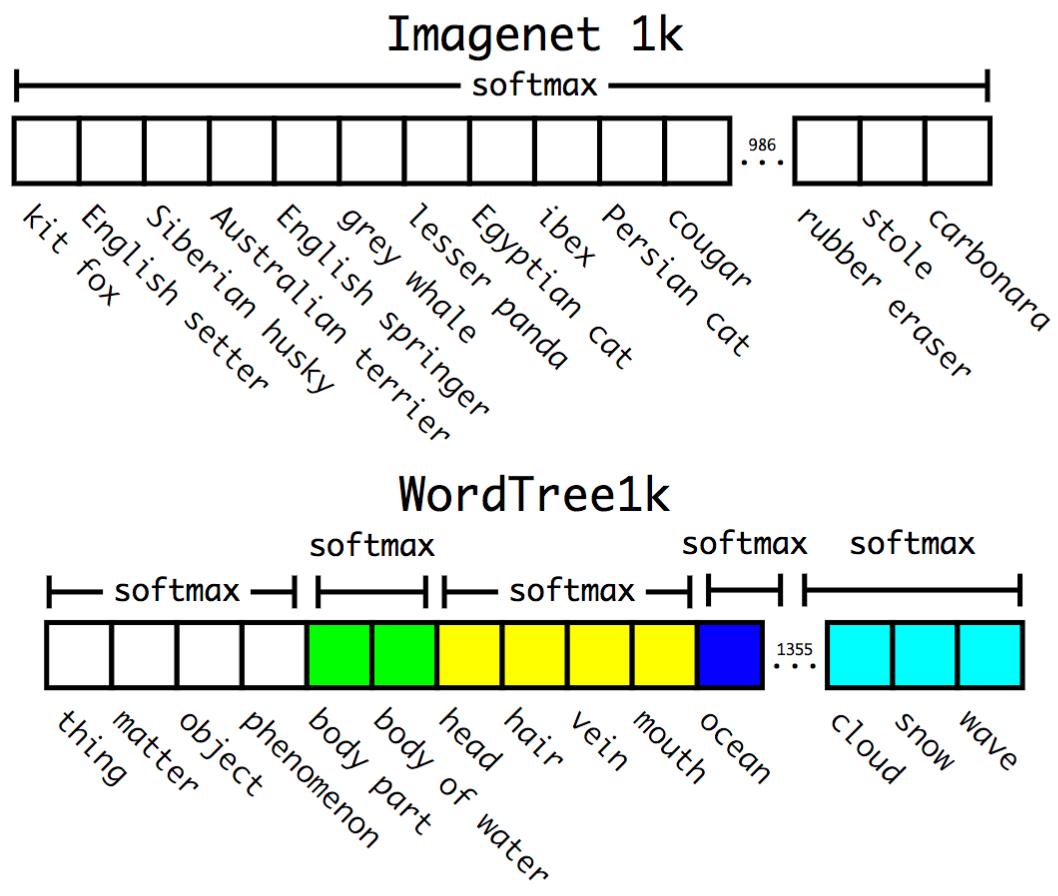
A combination between the COCO and the ImageNet datasets is used to train a YOLOv2-like architecture with 3 prior convolution layers instead of 5 to limit the output size. The model is evaluated on the ImageNet dataset for the detection task with around 200 labels. Only 44 labels are shared between the training and the testing dataset so the results are somewhat irrelevant. It gets a 19.7% mAP score overall the test dataset.
Mask Region-based Convolutional Network (Mask R-CNN)
Another extension of the Faster R-CNN model has been released by K. He and al. (2017) adding a parallel branch to the bounding box detection in order to predict object mask. The mask of an object is its segmentation by pixel in an image.

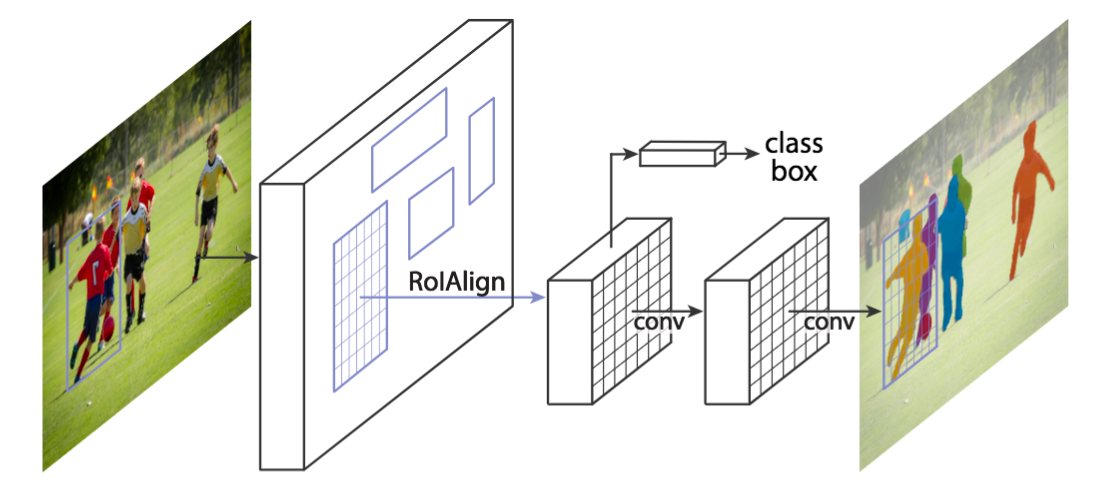
The Mask Region-based Convolutional Network (Mask R-CNN) uses the Faster R-CNN pipeline with three output branches for each candidate object: a class label, a bounding box offset and the object mask. It uses Region Proposal Network (RPN) to generate bounding box proposals and produces the three outputs at the same time for each Region of Interest (RoI).
The initial RoIPool layer used in the Faster R-CNN is replaced by a RoIAlign layer. It removes the quantization of the coordinates of the original RoI and computes the exact values of the locations. The RoIAlign layer provides scale-equivariance and translation-equivariance with the region proposals.
The model takes an image as input and feeds a ResNeXt network with 101 layers. This model looks like a ResNet but each residual block is cut into lighter transformations which are aggregated to add sparsity in the block. The model detects RoIs which are processed using a RoIAlign layer. One branch of the network is linked to a fully-connected layer to compute the coordinates of the bounding boxes and the probabilities associated to the objects. The other branch is linked to two convolutional layers, the last one computes the mask of the detected object.
Three loss functions associated to each task to solve are summed. This sum is minimized and produces great performances because solving the segmentation task improve the localization and thus the classification.
The Mask R-CNN have reached mAP scores of 62.3% for an IoU = 0.5, 43.4% for an IoU = 0.7 and 39.8% for the official metric over the 2016 COCO test-dev dataset.
Manual Selection to Delimit a Region of Interest
The EyeSpy Model allows the user to implement a gesture motion to isolate a specific object within an image of interest. As the selection process is manual, complex algorithms to determine the accuracy of bounding boxes and class probabilities with a single network in a single evaluation are not required. It therefore allows for real-time predictions.
Like all good ideas, the process is simple. Initially, the user captures a photograph using their handheld device (or can upload an image from their device’s camera roll), and this image is used as the image for input.

The flow begins when the app receives a notification from the device’s operating system that a gesture has begun within the area of the touchscreen that corresponds to the image. The app records x- and y coordinates associated with the event, e.g., in an array. In an event-driven software architecture, the operating system continues to provide notifications to the app, e.g., until the user completes the gesture. The app receives notification of an event and determines whether the event means that the gesture has ended. If the gesture has not ended, the app continues to record new x- and y-coordinates associated with the new event. When the app determines that the gesture is complete, it computes points corresponding to the minimum and maximum x- and y- coordinates, and, based on those points, defines a rectangle. The rectangle is then to define an area of interest within the image.

This model outperforms the state-of-the-art in the four COCO challenges: the instance segmentation, the bounding box detection, the object detection and the key point detection. The accuracy of the bounding box is limited only by the accuracy of the user’s gesture to isolate the object of interest.
Our testing of the app on various objects resulted in a high degree of accuracy (~90%+) of object identification when we manually bounded the object of interest within an image. This is likely as a result of the high level of sophistication in the model’s methods and systems for object recognition, but it follows that the user-generated bounding of objects greatly assists in the performance outcomes as more computational time is spent on object recognition rather than the four COCO challenges identified above and other issues such as latency and noise.

Conclusion
Our survey returned several strategies to overcome the object detection problem. Object detection models tend to infer localization and classification all at once to have an entirely differentiable network. Thus it can be trained from head to tail with backpropagation. Moreover, with the exception of EyeSpy, a trade-off between high performance and realtime prediction capability is made between the recent models. EyeSpy was the only model to perform highly across both categories: a mAP rate of 90% in real time. While this does not resolve the barrier to deep learning and automated boundary distinction, it does bypass the obstacle through coordinate inputs. The methodology limits assisting advancements relative to projects like artificial neural networks based applications, however the process could create rapid and significant advancements in applications to a) assisted deep learning; and b) inventions such as a gesture-based designation of regions of interest applications (eg: augmented reality lens of the headset being pursued by Snapchat, Microsoft, etc).
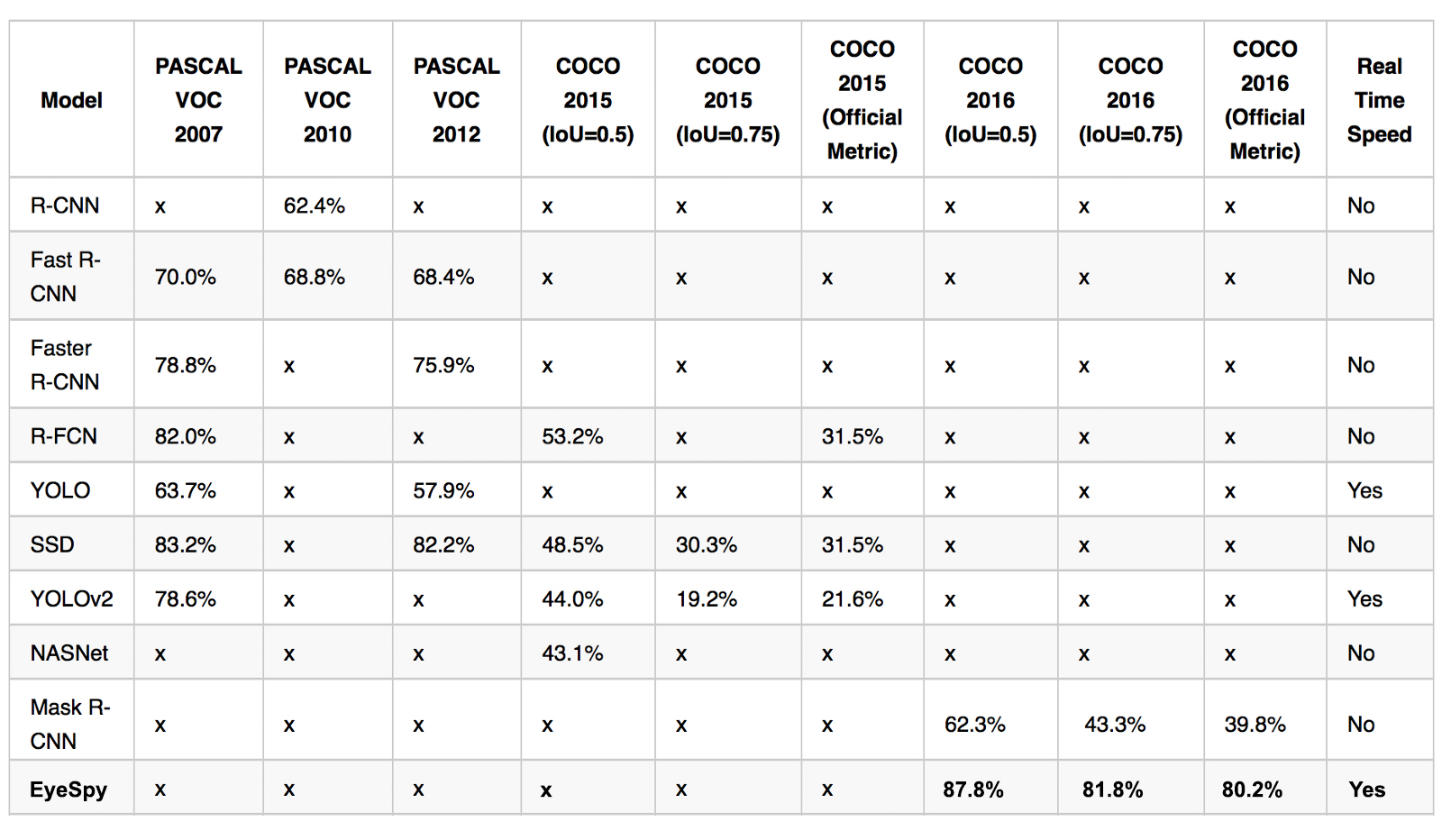
Overview of the mAP scores on the 2007, 2010, 2012 PASCAL VOC dataset and 2015, 2016 COCO datasets.
The models presented in this blog post are either accurate or fast for inference. However, with the exception of EyeSpy, they all have complex and heavy architectures. For example, the YOLOv2 model is around 200MB and the best NASNet around 400MB. Reduction of size while keeping the same performances is an active field of research to embed deep learning models into mobile devices.
¹:When Business Insider experimented with Blippar’s object recognition, the app identified a foot as a hand, a dining room table as a poncho, and a chair as a cradle.
²: The COCO challenge has developed an official metric to avoid an over generation of boxes. It computes a mean of the mAP scores for variable IoU values in order to penalize high number of bounding boxes with wrong classifications.
³: The entire architecture is inspired from the VGG16 model, thus it has 13 convolutional layers and 3 fully-connected layers.
⁴: The fastest Faster R-CNN has an architecture inspired by the ZFNet model introduced by M.D. Zeiler and R. Fergus (2013). The commonly used Faster R-CNN has an architecture similar to the VGG16 model and it is 10 times faster than the Fast R-CNN.
⁵: Except the last layer which is a fully connected layer.
⁶: It reduces the features space from the previous layers.
Leave a Reply
You must be logged in to post a comment.